[TOC]
MoDS: Model-oriented Data Selection for Instruction Tuning
Paper: https://arxiv.org/abs/2311.15653
核心思想
作者提出了一种针对模型做数据选择的框架,从质量、覆盖范围、必要性三个角度评估指令微调数据对于 LLM 指令微调的增益。
- 质量:指令本身的质量和相应回复/反馈的质量
- 覆盖范围:数据集内数据的多样性
- 必要性:对于特定 LLM 微调,指令数据的重要性和独特性
- 如果 LLM 无法针对该指令生成恰当的回复,那么这条数据是重要的/独特的
算法框架
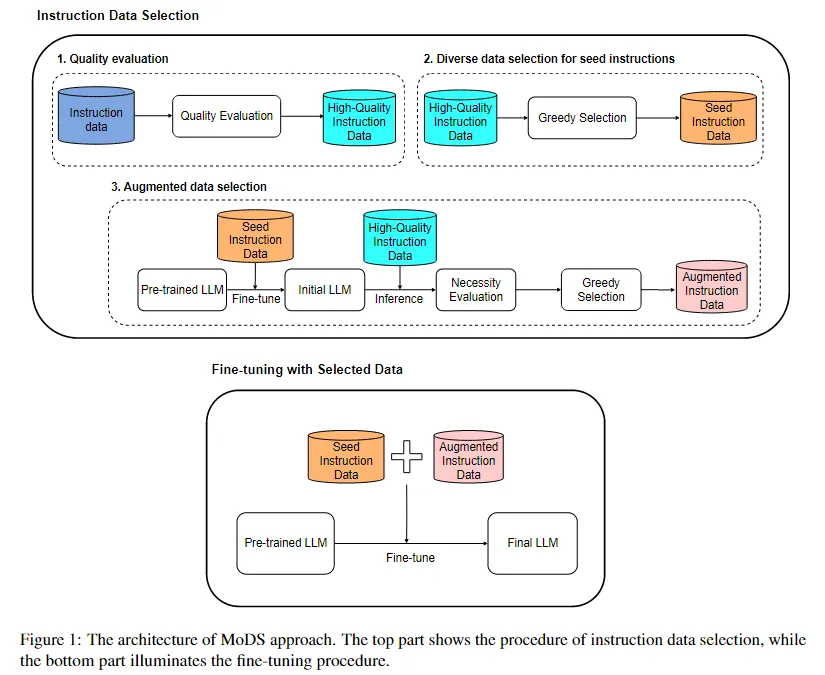
- 用奖励模型筛选高质量数据,得到高质量数据集
- 根据多样性选取种子数据,得到种子数据
- 增强指令数据
- 用种子数据训练 LLM,得到种子 LLM
- 种子 LLM 为高质量数据集中的不同指令生成回复
- 用必要性评分模型(筛选高质量数据时用的奖励模型)计算回复的得分,按照阈值过滤不必要数据
- 最后用选择出的数据微调模型
关键问题
不同的维度如何量化
- 质量
- 使用奖励模型为每个数据打分,按照阈值过滤低质量数据。
- 覆盖度(多样性)
- 使用 BERT 计算句子表示,计算句子之间的距离
- 使用 K-Center 方法,贪心选择样本
- 必要性
- 用种子数据训练模型,为高质量数据生成回复
- 用奖励模型评估必要性(奖励模型和质量评估的模型相同)
补充:K-Center 方法

- 先选择一个初始中心点,然后迭代增加新的中心点
- 每一步选择离现有中心点最远的点作为新的中心点
- 公式说明:对非中心点集合中的点,每一步找到一个离最近中心点最远的点。
实验结果
主要结果:
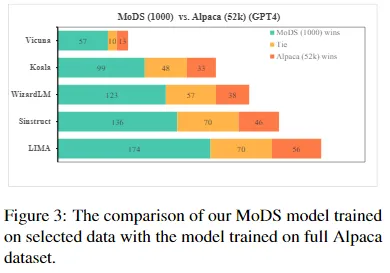
对比实验:
总结
本文提出了一种数据选择框架,筛选出一些高质量的种子数据,并实现指令增强,并用必要性评分模型过滤不必要的数据,再混合两者微调模型。