PromptBERT: Improving BERT Sentence Embeddings with Prompt
Abstract
本文认为,原始BERT模型在句子语义相似度任务上表现不佳的原因:
- 静态token嵌入偏差 (static token embeddings biases)
- 无效的BERT层 (ineffective BERT layers)
而不是因为BERT生成的句子表示的余弦相似度高
本文的工作:
- 提出了一个基于prompt的句子嵌入方法(将sentence embeddings task重构为fill-in-the-black 问题)
- 减少了静态token嵌入偏差
- 让原始的BERT更有效
- 讨论了两种Prompt表示方法以及三种prompt搜索方法
- 通过template denoising技术提出了一个新的无监督训练目标
Instruction
1️⃣近年来,在句子表示上,基于BERT的SimCSE等模型有出彩的表现,但是原始的BERT表现很差,甚至不如传统Word Embedding方法GloVe。
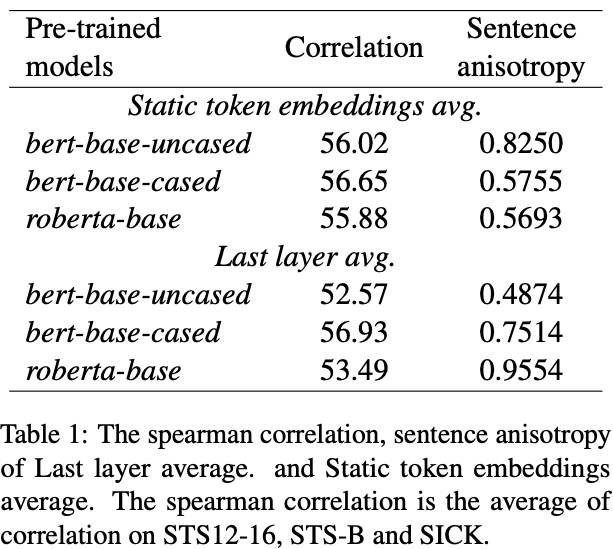
2️⃣有一些研究认为BERT在句子语义相似任务上表现差是因为各向异性(anisotropy)。但是比较静态的BERT词向量与最后一层词向量平均池化后的表现(static > last layer)显示,anisotropy不是主要原因。
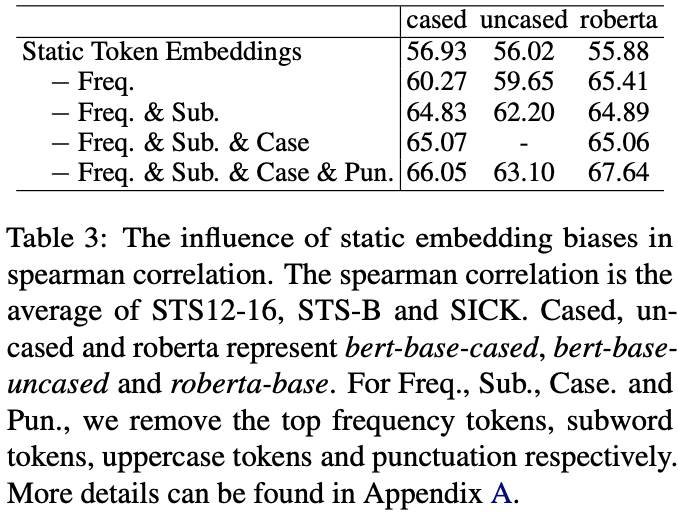
3️⃣本文发现,原始的BERT层实际上损害了句子表示的质量。我们发现,分布的偏差不仅和token的频率有关,还对WordPiece中的subword敏感。【通过移除这种高频的subwords或者punctuation,并取其他token的embeddings作为sentence embeddings甚至可以超过BERT-flow和BERT-whitening的表现】
手动移除偏差token需要大量人力,本文受到prompt方式的启发,提出了一种基于prompt,用模版从BERT中获取句子表示的方法。
本文提出的方法也可以用于微调。作者发现,通过不同的模版,prompt可以提供更好的生成positive pairs的方法。
最后,作者提出了一种基于prompt的对比学习方法,这种方法通过template denoising在无监督的设置下利用BERT的能力,能够显著缩短有监督和无监督的表现差距。
Related Work
略
Rethinking the Sentence Embeddings of Original BERT
作者认为,原始BERT在句子相似度任务上表现不佳的原因是:
- ineffective BERT layers
- static token embeddings biases
作者通过自己观察到的两种现象验证自己的观点:
Original BERT layers fail to improve the performance.
衡量句子表示各向异性的方法:
$n$为句子的数量,$M$为sentence encoder,$s$为句子
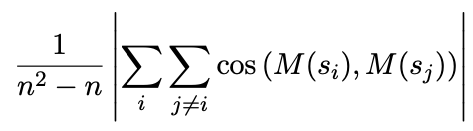
比较static embeddings和last layer的平均池化(句子表示)
经过BERT的层之后,句子之间的Correlation下降了。
各项异性和句子表示的表现没有显示出关联性。
(疑问:这里的句子编码是Cross-Encoder还是Bi-Encoder?)
Embeddings biases harms the sentence embeddings performance.
没理清楚逻辑,之后补
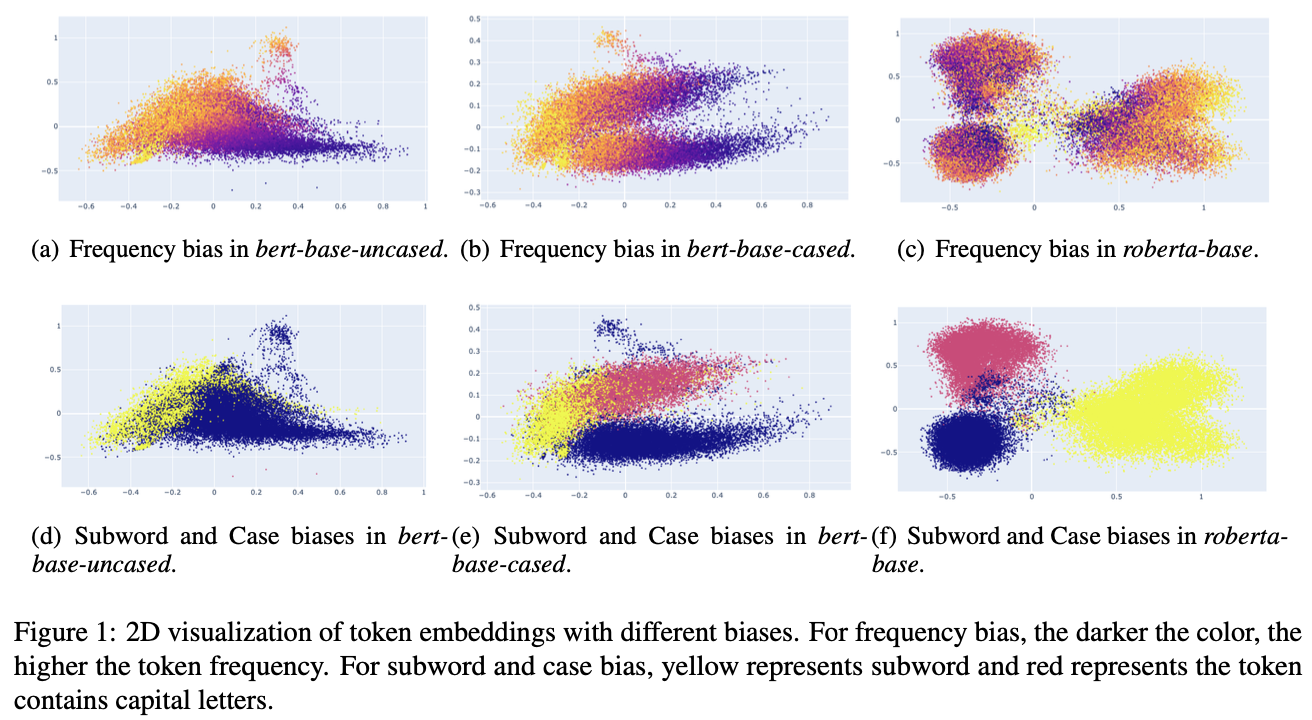
- token embeddings受到token频率(token frequency)、子词(subwords in WordPiece)的影响
- token embeddings 分类:
- 小写开头(lower begin-word tokens)
- 大写开头(uppercase begin-word tokens) 【bert-cased】
- 子词(subword tokens)
下图展示了token frequency,subword对token embeddings分布的影响
移除high frequency token,部分sub word, case等就能带来提升
Prompt Based Sentence Embeddings
核心问题:
- 怎样用prompt表示句子
- 对于sentence embeddings,怎样找到更好的prompt
represent sentence with the prompt
使用模版:“[X] means [MASK]”
两种方法:
直接用[MASK]对应的token embedding作为sentence embedding
$h=h_{[MASK]}$
用[MASK]对应的token embedding,用一个MLM分类器选择最好的top-k个token
$h=\dfrac{\sum_{v\in V_{top-k}}W_vP([MASK]=v|h_{[MASK]})}{\sum_{v\in V_{top-k}}P([MASK]=v|h_{[MASK]})}$
缺点:
- 因为使用静态token嵌入取平均得到句子表示,仍然会受到偏差(biases)的影响
- 在下游任务上不容易fine-tune
作者最终采用了第一种方式
prompt search
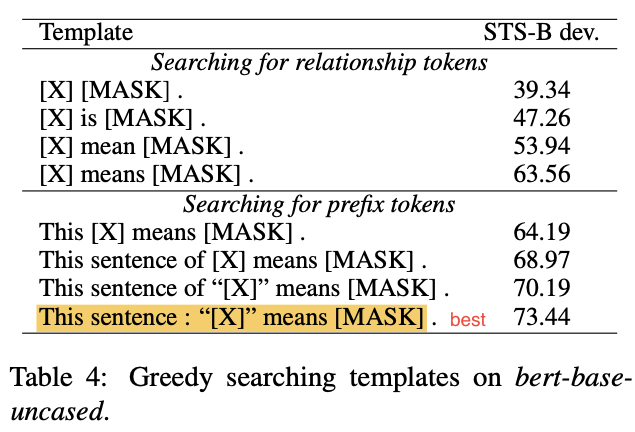
作者讨论了3种方法用于搜索模板:
手工
将模版分成两部分:
- 关系token:用于句子和「MASK」之间
前缀token:用于修饰句子(「X」前)
用贪心的方法搜索
基于T5生成
用T5生成的最好模版:
“Also called [MASK]. [X]”.
效果比手工生成的差
OptiPrompt (Factual probing is [mask]: Learning vs. learning to recall)
用连续模版代替离散模版,在STS-B上能将效果提高到80.90
prompt based contrastive learning with template denoising
常用的方法:dropout,adversarial attack, token shuffling, cutoff and dropout in the input token embeddings
作者的方法:
用不同的模版对同一个句子生成句子表示,取为positive pairs。
方法描述:
给定句子$x_i$
- 用一个模版计算对应的句子表示$h_i$
- 计算模版偏差$\hat{h_i}$:直接送入一个模版和相同的template ids
- 用$h_i$$-\hat{h_i}$作为降噪后的句子表示
用$h_i’,\hat{h_i’}$表示用另一个模版生成的句子表示
优化下述训练目标:
$l_i=-log\dfrac{e^{cos(h_i-\hat{h_i}, h_i’-\hat{h_i’})/t}}{\sum_{j=1}^{N} e^{cos(h_i-\hat{h_i},h_j’-\hat{h_j’})/t}}$
Experiments
- 数据集
- STS
- STS-B
- SICKR
- Baselines
- non fine-tuned:
- GloVe
- BERT-flow
- BERT-whitening
- fine-tuned
- IS-BERT
- InferSent
- Universal Sentence Encoder
- SBERT
- SimCSE
- ConSERT
- non fine-tuned:
- Implementation Details
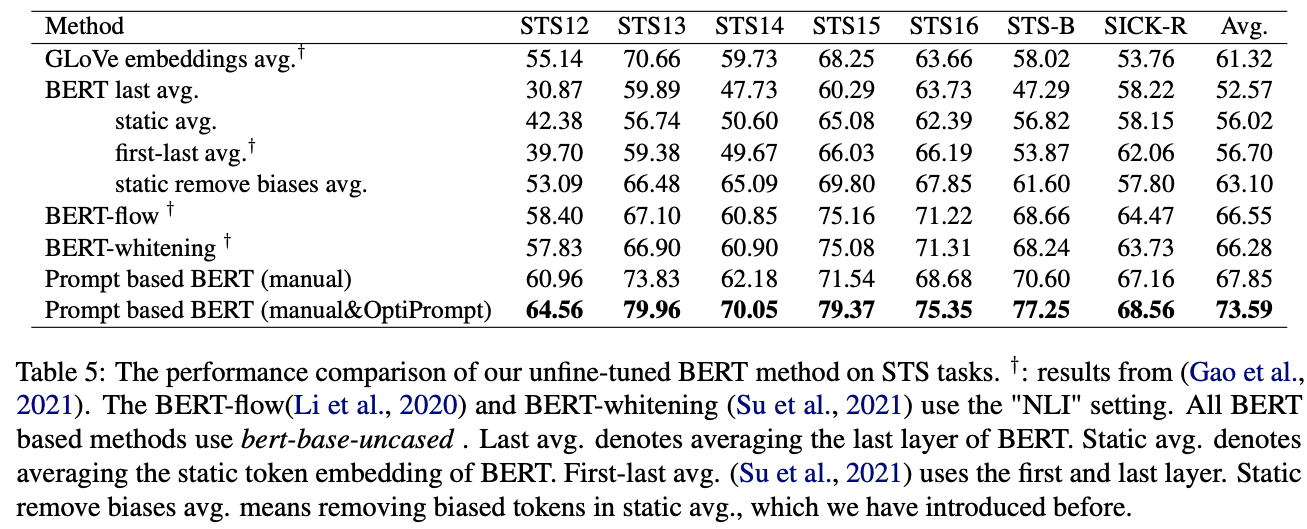
Non fine-tuned
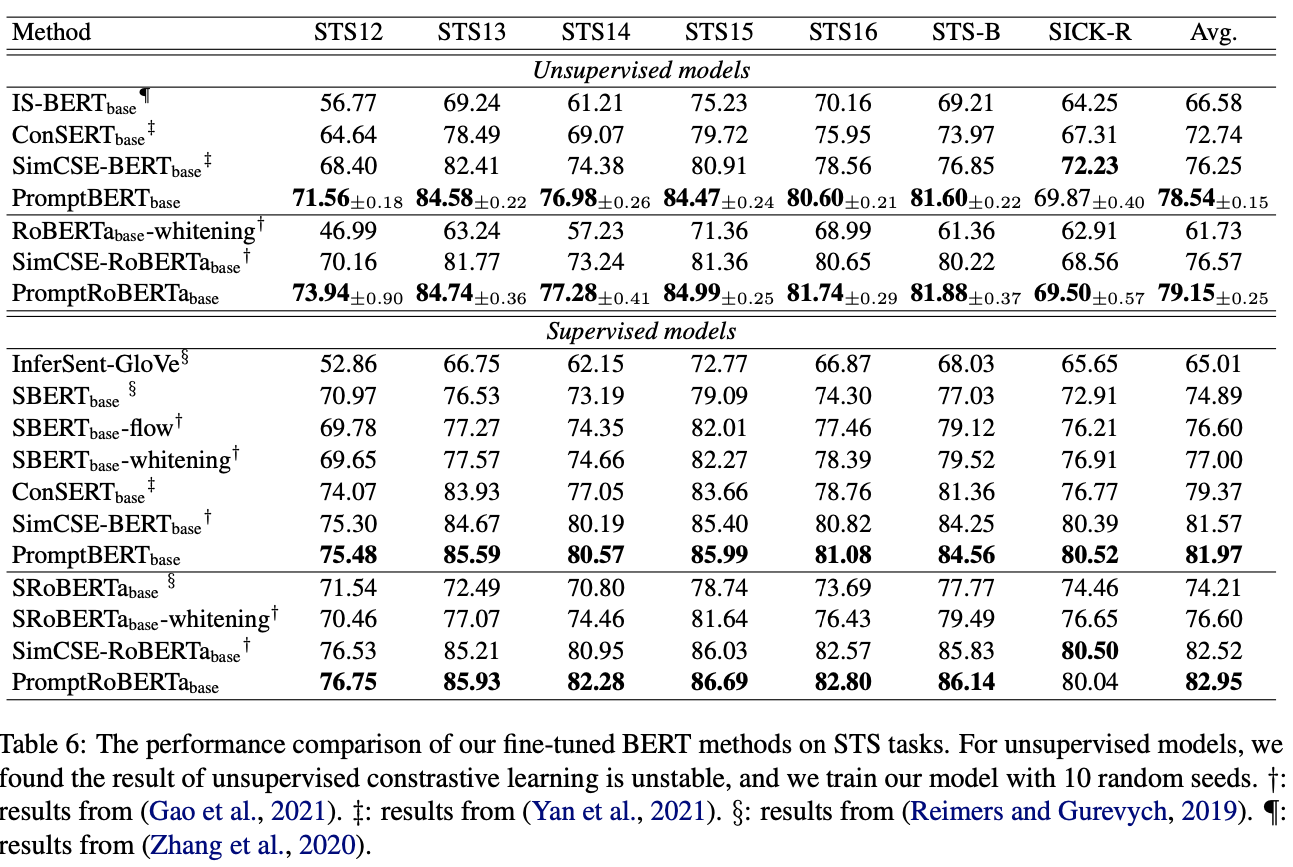
fine-tuned
ablation

Discussion
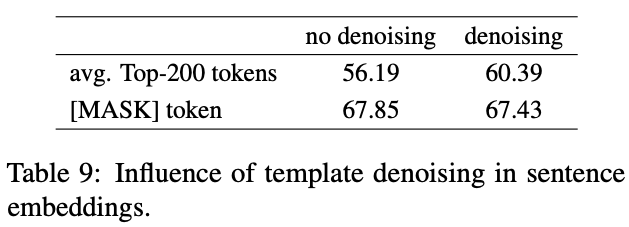
Template Denoising
该方法可以移除无关的词汇,例如nothing, no ,yes
只在对比训练目标函数中使用了该方法,可以帮助消除偏差
Stability in Unsupervised Contrastive Learning
用10个不同的随机种子训练模型,与SimCSE对比,PromptBERT的最好和最坏结果差值只有0.53%,SimCSE的差值为3.14%
