CS224N Lecture 8 Notes
任务: Neural Machine Translation
结构: Seqence-to-Sequence
技巧: Attention
注:本文所用图片为从课程slides中截取
之前的课程讲到的任务都没有涉及整个句子的输出,Lecture 8的内容就着眼与这个部分。类似的任务有:
- 翻译
- 对话
- 文本摘要
类似的任务都是需要输入一个句子(或者更长)并且输出一个句子,Sequence-to-Sequence模型适合解决这类问题。
统计机器翻译 SMT(Statistical Machine Translation)
翻译模型
给定一种语言的句子$x$ (Sentence),求出与之对应的可能性最大的另一种语言的句子$y$
SMT的训练
通过平行语料训练,相当于一个解码的过程。主要通过统计方式,用启发式搜索算法计算
 )
)
存在以下问题:
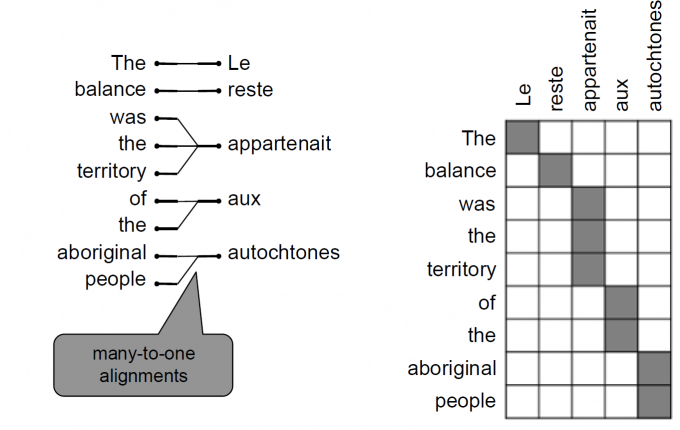
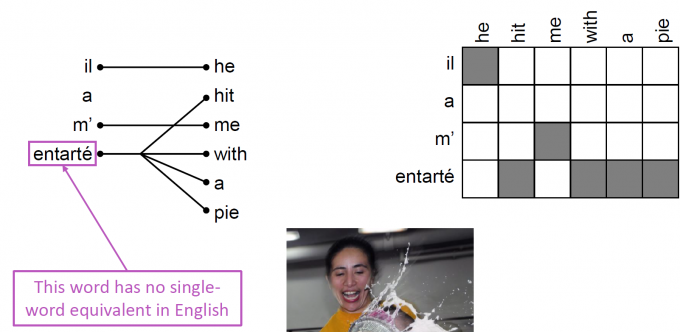
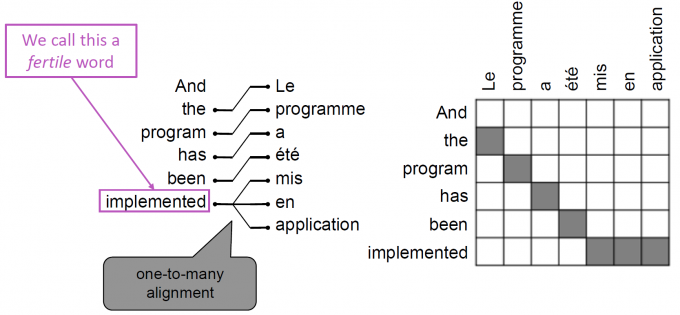
对齐问题(alignment):
两种语言的词在句中的位置可能不是一一对应,可能出现无对应,一对多,多对一,多对多(短语对应短语)等情况出现
- 多对一
- 一个词对应一个短语
- 一对多
- 多对一
- 一词多义
神经机器翻译 NMT(Nerual Machine Translation)
Seq2Seq模型
Seq2Seq模型是一种端到端(end-to-end)模型
由两个循环神经网络组成(RNN)
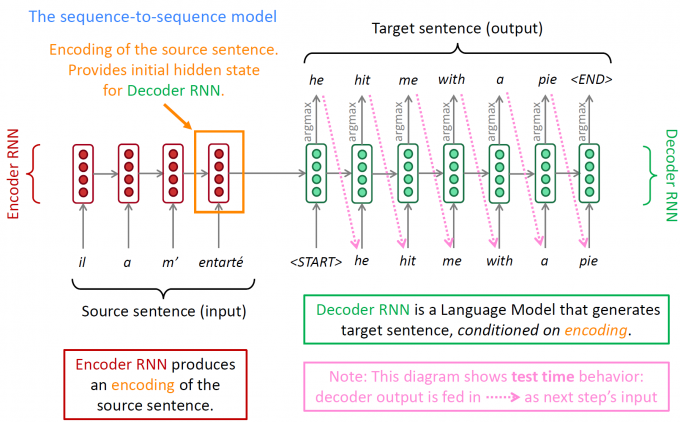
Encoder:
将输入的序列编码为一个固定大小的“上下文向量”
Encoder的最后一个时间步输出的隐藏状态$h$就是“上下文向量”$C$,其网络常采用LSTM。
Encoder会逆序处理输入的序列,这样可能让EEncoder最开始读入的信息对应最后的输出。Decoder的获取的第一个输入可能会提高其生成合适序列的概率。
Decoder:
将encoder产生的“上下文向量”用于初始化Decoder的隐藏状态。
Decoder是一个语言模型(Language Model,LM)。每个时间步生成的内容又作为下一个时间步的输入。当隐藏状态设置好,就可以开始生成序列了。
生成序列:
Decoder的输入是一个代表开始的特殊表示
<start>。并且需要在输入的最后加上表示结束的特殊表示<EOS>,同时这个表示也是输出的结束标志。接下来就按照时间步计算输出序列即可。
训练:
在Seq2Seq模型中,定义预测序列的交叉熵(cross-entropy loss)作为模型损失,训练目标就是最小化这个损失。
NMT
神经机器翻译采用Seq2Seq模型结构,由两个RNN网络构成。一个RNN作为编码器, 一个RNN作为解码器构成。
- 编码器(Encoder):
负责提取输入的句子的信息,并传递给解码器使用。输出的是输入句子的编码信息。 - 解码器(Decoder):
解码器实际上是一个语言模型(Language Model, LM),作用是通过编码器传来的信息生成目标语言的句子。 注意:
解码器起始输入为
<start>。解码器每个单元产生的输出会作为下一个单元的输入。直到产生一个<end>编码器和解码器之间没有连接,因此输入语句的长度是任意的,输出语句的长度也是任意的,二者的长度并不一致。
网络结构如下:
模型训练
模型直接计算:
其中$y$为目标句子,$x$为输入的句子。$y_i$是输出的第$i$个单词。上式描述了解码器生成句子$y$的概率。
训练,最小化损失函数。Decoder每一个时间步的负log损失相加,就是模型的总损失:
Decoder怎样求出目标句子
- 基础方法:贪心编码
- 每次都求出当前评分最高的句子
- 缺点:不能回退
- 暴力方法:搜索所有可能编码
- 每次都搜索所有可能行
- 缺点:计算复杂度高,代价昂贵
- Beam search decoding
- 每次选出前$k$种可能性最高的词,然后对每种可能作出评分,留下$k$个可能性最高的编码
- 停止条件:
- 规定数目的编码终止(生成了
<end>) - 达到规定的时间步
- 规定数目的编码终止(生成了
对句子的评分:
上述每种方法,都需要对句子进行评分然后比较,评分公式如下:
改进:由于句子长度对评分有所影响(句子越长,评分越低)因此对评分做规范化(Normalize)处理
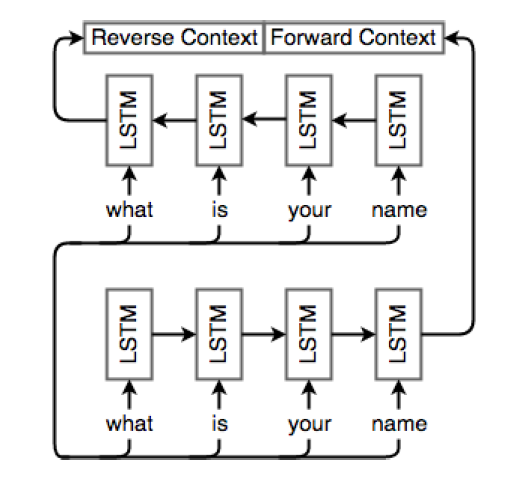
改进:双向循环神经网络
最基本的NMT结构中,编码器和解码器中的信息都是单向流动的,但是在句子中,词和词之间的依赖不一定是单向的,因此,通过在编码器和解码器中增加一个方向的RNN,实现双向的RNN结构,有助于获取词和词之间在两个方向上的依赖信息。
由于采用了两个方向的RNN,编码层产生的“上下文向量”也就有了两个:一个正向,一个反向(reverse context vector, forward context vector)。用于初始化解码器中的对应方向的RNN网络。
采用双向循环神经网络的编码器:
NMT的优缺点
优点
- 表现比SMT更好
- 只需要一个单独的神经网络就能完成训练
- 更少的特征工程
缺点
- 可解释性差
- 很难控制
NMT的难点
- 超出词汇表(out-of-vocabulary)
- 领域不匹配(Domin mismatch)
- 难以从长文本中获取信息
- 一些语言的训练语料很少(NMT需要大量训练语料)
- 偏见(训练出的模型在处理一些句子时会出现偏向某一个性别的现象)
- 可解释性差
注意力机制 (Attention)
来源:
一个输入中的不同部分应该具有不同等级的重要性。
例如:
input: the ball is on the filed
句中的每个单词的重要性是不同的,ball和filed两个单词的重要性明显更高。
作用:
注意力机制的作用就在于:
为解码器的每个时间步都提供了输入句子的全局信息(这个信息经过注意力机制后强调了重点部分),因此在不同的时间步,解码器可以决定哪些输入的内容在当前是重要的。
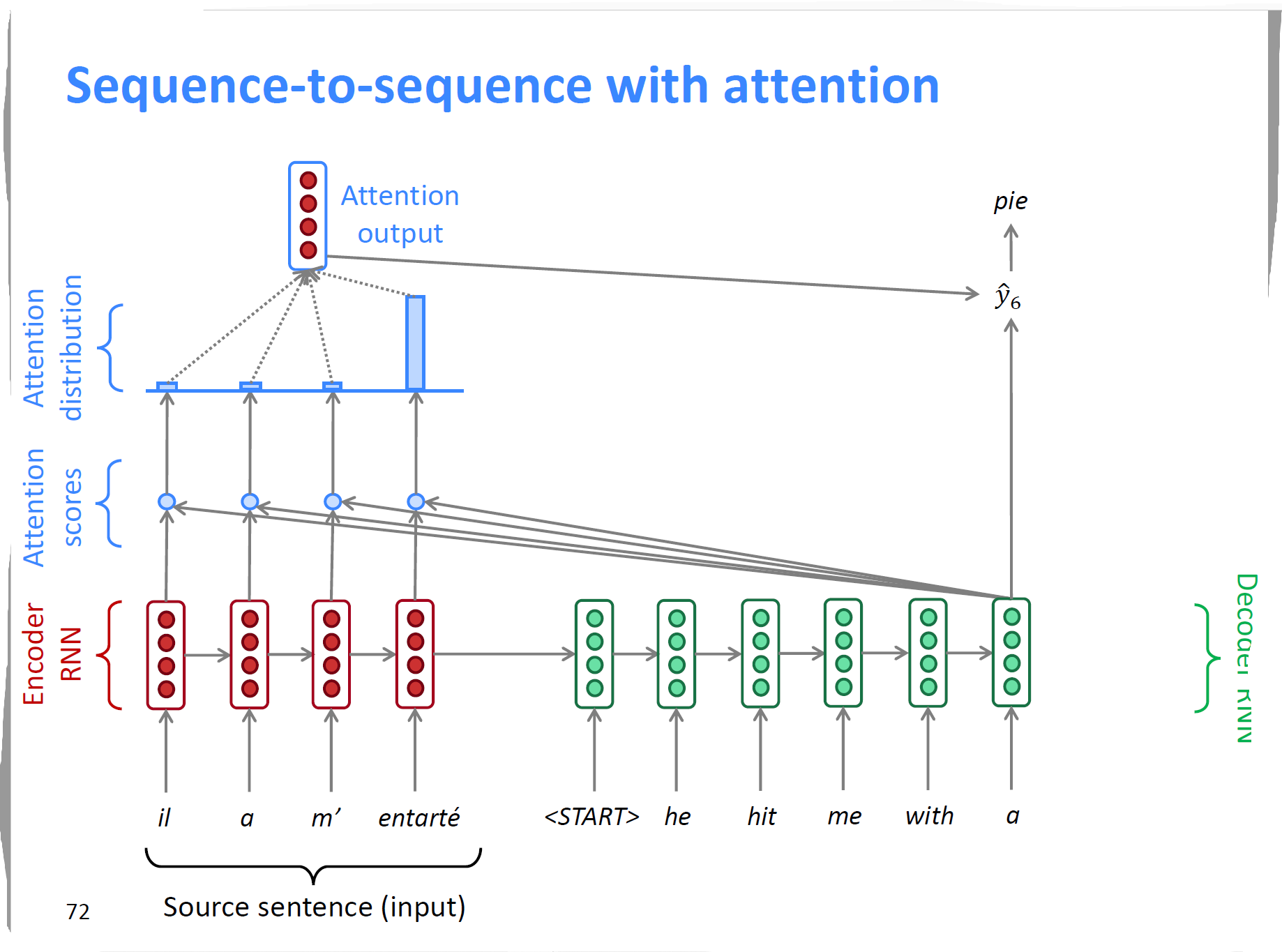
注意力机制图示:
为什么要使用注意力机制:
基本的NMT模型中,编码器的最后一个时间步的输出隐状态传送到解码器中作为输入。当句子较长的时候,很难获取到较远时间步的信息。
引入注意力机制就是为了捕获原句中的所有信息(重要信息)
结构
上图为解码器在最后一个时间步使用Attention的图示。
注意力机制获取编码器中每个时间步的输出,结合解码器中当前时间步的输出,通过
scores函数求出相应的评分,得到其分布情况(Attention Distribution)。而后通过softmax得到注意力层的输出(Attention output)。然后将注意力层的输出和解码器该时间步的隐含状态拼接起来按照和未使用注意力机制时一样的处理方式处理。具体的公式如下:
score函数
使用softmax函数计算分布:
计算Attention output
连接注意力层的输出和解码器的隐含状态:
- 其中$e^t$表示attention scores, $\alpha^t$是其分布,$a_t$是注意力层最终的输出,$s_t$是当前解码器时间步输出的隐藏状态。
注意力机制的作用
- 提高NMT的表现,打破NMT的瓶颈,并且对梯度消失问题有所帮助
为NMT模型提供了一定的可解释性
- 通过注意力层的评分,可以观察到句子中哪些信息比较重要
- 网络自学习到了关于不同语言单词对齐(alignment)的信息
总结
第8课主要涉及以下内容:
- Machine Translation的历史:SMT
- 基本的Neural Machine Translation(NMT)架构Seq2Seq
- NMT的优缺点及难点
- 引入注意力机制解决编码器捕获长序列信息的瓶颈
PS: 对于Lecture内中提及的其他模型及对NMT结果的评估部分内容未完成,后续逐渐补充